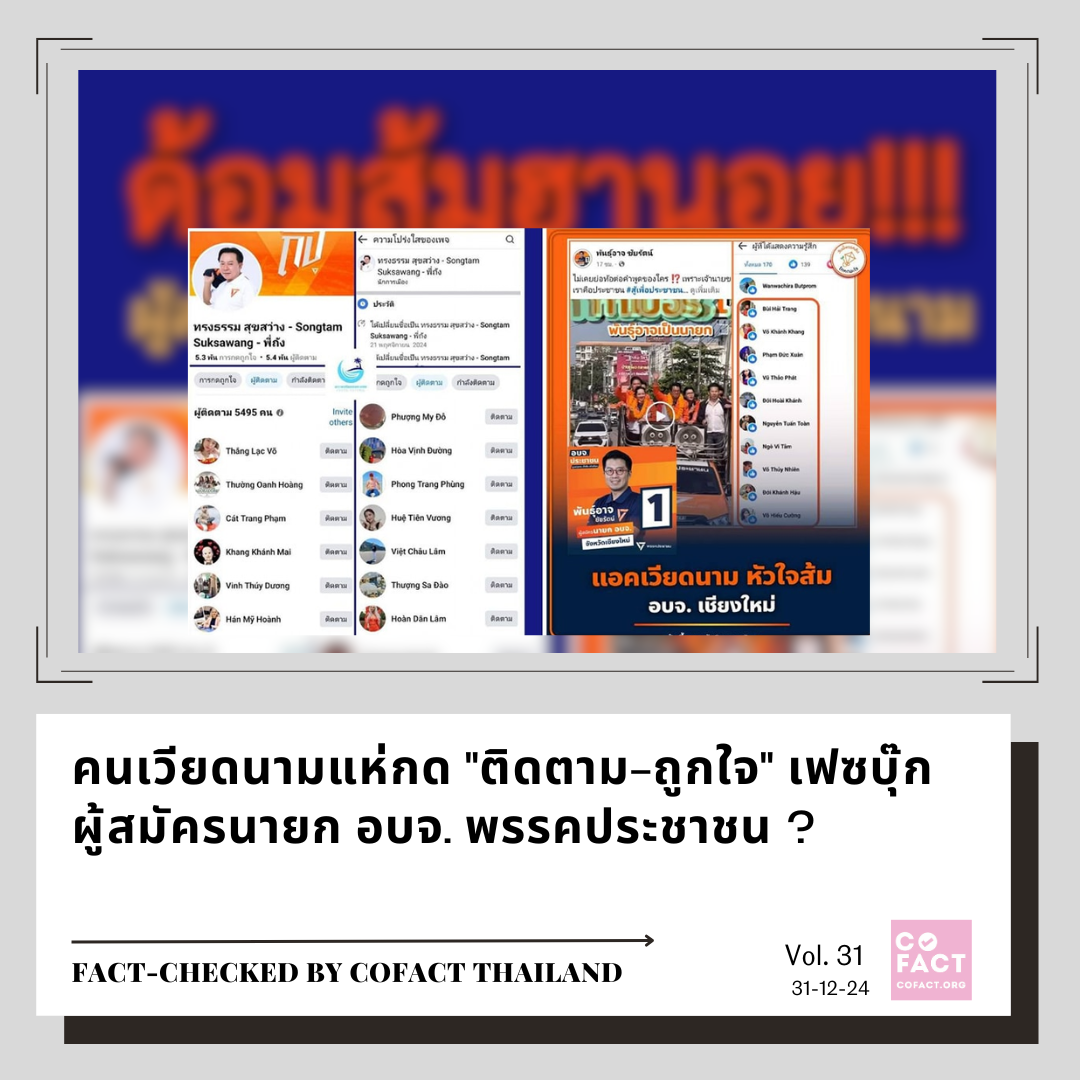
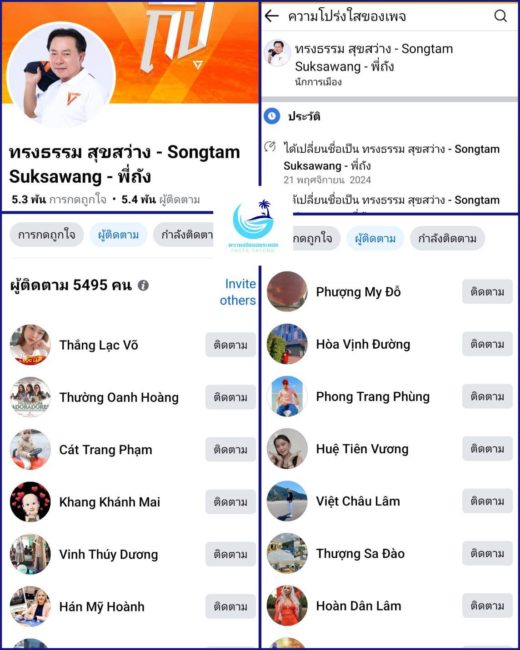
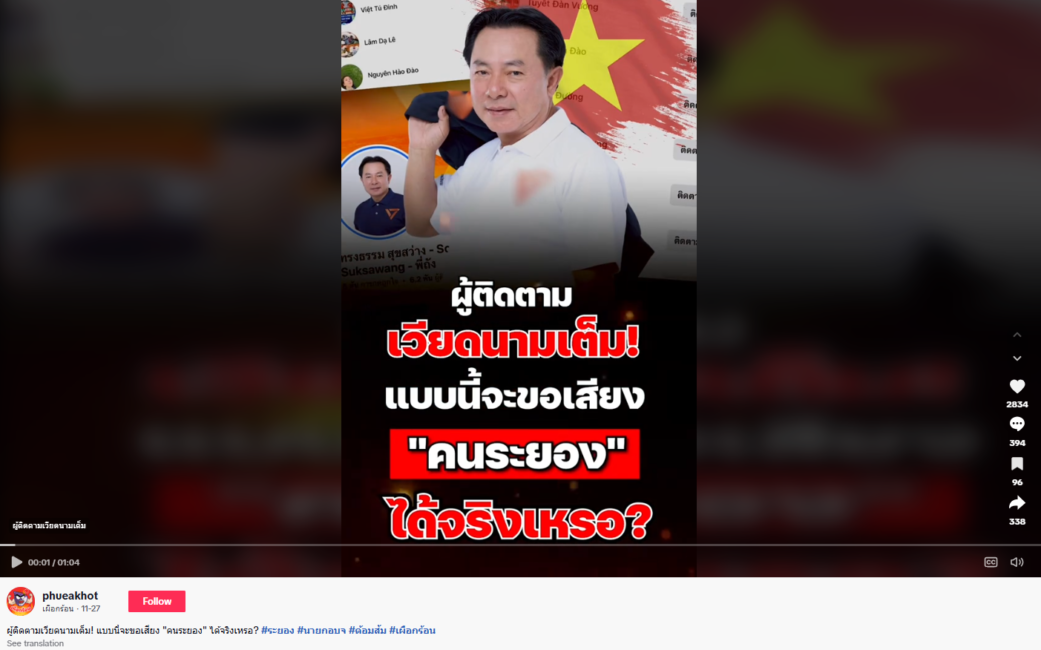
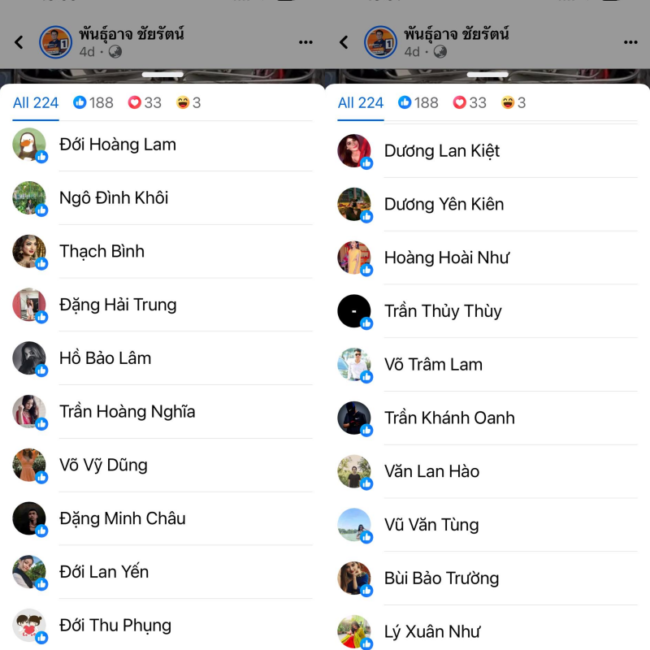
รายการ “Cofact Live Talk” เผยแพร่ทางเพจเฟซบุ๊ก “Cofact โคแฟค” ดำเนินรายการโดย สุภิญญา กลางณรงค์ ผู้ร่วมก่อตั้งภาคีโคแฟค (ประเทศไทย) ชวนสนทนาธรรมในหัวข้อ “ขอสติมาปัญญามี อย่าหลงเชื่อโดยไม่ตรวจสอบ” กับ พระมหานภันต์ สนฺติภทฺโท ผู้ช่วยเจ้าอาวาสพระอารามหลวง วัดสระเกศราชวรมหาวิหาร และประธานกรรมการมูลนิธิสถาบันการจัดการวิถีพุทธเพื่อสุขและสันติ (IBHAP Foundation)

โดย พระมหานภันต์ เริ่มต้นด้วยการยกเหตุการณ์ “9 แรกของปี” หรือวันที่ 9 ม.ค. 2568 อันเป็นวันก่อนหน้าเผยแพร่รายการครั้งนี้ ซึ่งหลายคนก็ถือเป็นฤกษ์งามยามดี มากล่าวเป็นกลอน ว่า..
“วันที่ 9 แล้วไง? ใจไม่ก้าว
ยังติดหล่มจมเรื่องราวคราวหนหลัง
วิธีคิดติดกรอบชอบกับชัง
ชีวิตฝังติดตัวกู (อัตตา) อยู่ร่ำไป
วันที่ 9 ยิ่งแล้วใหญ่หากใจกร้าว (โหดร้าย-รุนแรง)
คิดพูดทำก้าวร้าวถึงไหนไหน
ไม่รู้หรอกอ่อนโยนนอกแข็งแกร่งใน
แข็งเรื่อยไปสุดท้ายแหลกแตกยับเยิน
วันที่ 9 ก้าวให้พ้นตัวตนเก่า
ก้าวข้ามเขลาข้ามฉลาดข้ามขลาดเขิน
ก้าวหนึ่งก้าวใกล้หนึ่งใกล้เหมือนไกลเกิน
เพียรก้าวเดินพึงก้าวถึงซึ่งสักวัน”
ทั้งนี้ สืบเนื่องจากทิศทางการเมืองในสหรัฐอเมริกา ประกอบกับความต้องการลดต้นทุน ทำให้แพลตฟอร์มสื่อสังคมออนไลน์ในสหรัฐฯ อย่างเฟซบุ๊ก ตัดสินใจเลิกใช้บริการองค์กรภายนอก (Third-party) ในการตรวจสอบความถูกต้องของข้อมูล โดยจะหันไปใช้ระบบคำเตือนของชุมชน (Community Notes) คือให้ผู้ใช้งานแพลตฟอร์มนั้นๆ ช่วยตรวจสอบกันเองว่าโพสต์ต่างๆ ที่ปรากฏมีความถูกต้องหรือไม่ ซึ่ง พระมหานภันต์ กล่าวถึงข่าวนี้ว่า จริงๆ แล้วต้นทุนป้องกันการระบาดของข่าวลวงก็เหมือนกับต้นทุนในการรักษาสุขภาพ คือเรามองไม่เห็น
แต่สุดท้ายเมื่อไม่รักษาสุขภาพ เราก็จะกลายเป็นผู้ป่วยติดเตียงบ้าง ป่วยโรคเรื้อรังบ้าง สุดท้ายต้นทุนทั้งในแง่ทรัพย์สินและจิตใจก็จะมากมายมหาศาล เช่นเดียวกับการที่ไม่ช่วยกันป้องกันข่าวลวง โดยเฉพาะข่าวลวงที่สร้างความเกลียดชังระหว่างเชื้อชาติ-ศาสนา ราคาที่ต้องจ่ายหากไม่ป้องกันก็จะมหาศาลมาก ยังไม่นับรวมมิจฉาชีพที่รุกเข้าไปในทุกแวดวง
ประการต่อมา ในศาสนาพุทธมีคำสอนว่า “สัตว์โลกย่อมเป็นไปตามกรรม” ซึ่งเริ่มตั้งแต่ “มโนกรรม” หมายถึงวิธีคิด ค่านิยม “วจีกรรม”การพูดหรือการสื่อสาร สุดท้ายคือ “กายกรรม”หรือการลงมือทำ รวมถึงบทบาทระหว่างปัจเจกกับสังคม มีตัวอย่างการบวชเป็นพระภิกษุสงฆ์ ซึ่งเมื่อปัจเจกชนที่ต้องการพ้นทุกข์ต้องการจะบวชก็จะต้องได้รับรองจากพระอุปัชฌาย์และคณะสงฆ์ ดังนั้นเช่นเดียวกับในที่ทำงานหรือในสังคม ที่ไม่ควรให้มีลักษณะผลักภาระให้เป็นของปัจเจกหรือสังคมแต่เพียงฝ่ายเดียว

พระมหานภันต์ กล่าวต่อไปถึงศีลข้อ 4 ซึ่งครอบคลุมทั้งการพูดเท็จ พูดส่อเสียด พูดคำหยาบและพูดเพ้อเจ้อ และถือการทำคณะสงฆ์แตกแยกกันเป็นกรรมหนัก (อนันตริยกรรม) เมื่อเทียบกับบริบทปัจจุบันที่หลายคนไม่ว่าตั้งใจหรือไม่ตั้งใจ คือการ “พูดไม่หมดแล้วทำให้เข้าใจผิด” โดยจะพบในหลายๆ เพจที่เลี่ยงข้อกล่าวหาสื่อสารด้วยข้อมูลที่ไม่จริงด้วยการพูดครึ่งๆ กลางๆ แต่การพูดความจริงครึ่งคำก็เท่ากับพูดโกหกเต็มคำ ในทางศาสนาพุทธถือเป็นเรื่องรุนแรง และมีตัวอย่างมากมายเกี่ยวกับการพูดที่ทำให้เกิดความแตกแยก
หนึ่งในเหตุการณ์สำคัญคือ “ภิกษุในเมืองโกสัมพีวิวาทกัน” ที่มาที่ไปของเรื่องนี้มาจาก พระ 2 รูปคือ พระธรรมกถึก (พระนักเทศนาธรรม) เข้าห้องน้ำแล้วลืมเทน้ำและคว่ำภาชนะที่ใช้ตักน้ำ ซึ่งเป็นวินัยของสงฆ์ที่พระพุทธเจ้าบัญญัติไว้ จากนั้นพระวินัยธร (พระที่แม่นยำเรื่องข้อวินัยสงฆ์) ที่ใช้ห้องน้ำต่อก็ถามพระธรรมกถึกว่าลืมเทน้ำใช่หรือไม่ พระธรรมกถึกตอบยอมรับ ในเบื้องต้นพระวินัยธรบอกว่าไม่รู้ไม่เป็นไร
ปัญหาเกิดขึ้นหลังจากนั้น เมื่อพระวินัยธรไปเล่าเรื่องนี้ให้ลูกศิษย์ของตนเองฟัง บอกว่าพระธรรมกถึกได้เทศนาสั่งสอนผู้คนทั่วไปแต่ไม่รู้เรื่องวินัยสงฆ์ ลูกศิษย์ของพระวินัยธรจึงไปเล่าต่อกับลูกศิษย์ของพระธรรมกถึก และเมื่อลูกศิษย์ของพระธรรมกถึกไปถามพระสงฆ์ผู้เป็นอาจารย์ พระธรรมกถึกได้ย้อนว่าแล้วพระวินัยธรเป็นผู้ทรงวินัยจริงหรือ ขนาดพูดยังพูดไม่จริง เพราะตอนที่พบเห็น ตนก็ถามแล้วว่าจะให้แก้ไขอย่างไร แต่พระวินัยธรกลับบอกว่าไม่เป็นไร หากบอกว่าเป็นอาบัติจะได้จัดการให้เรียบร้อยไปแล้ว
“จากกลุ่มลูกศิษย์พระ เป็นลูกศิษย์ฆราวาส แล้วสุดท้ายก็ขยายไป ในคัมภีร์ถึงกับบอกว่าแม้แต่บนสวรรค์เทวดาก็แบ่งฝักแบ่งฝ่าย แล้วพอทะเลาะกันแม้แต่พระพุทธเจ้าไปห้าม พระทั้งกลุ่มที่กำลังทะเลาะกันก็บอกด้วยภาษาที่โลกปัจจุบันอาจจะแปลว่า ‘ขอพระองค์อย่ายุ่ง’ โทสะครอบงำถึงขนาดไม่เกรงใจแม้แต่พระพุทธเจ้า พระพุทธเจ้าต้องเสด็จปลีกไปเพื่อจำพรรษารูปเดียว” พระมหานภันต์กล่าว
พระมหานภันต์ เล่าต่อไปว่า บทสรุปของเหตุการณ์ที่ลุกลามบานปลายนี้ กลายเป็นฆราวาสที่คิดได้ก่อนนักบวช โดยเห็นว่าการที่ต่างฝ่ายต่างทะเลาะกันแบบนี้จนพระพุทธเจ้าปลีกออกไปทำให้ไม่มีโอกาสได้ฟังธรรม จึงไปขอให้คณะสงฆ์เลิกทะเลาะกัน ในตอนแรกบรรดาพระภิกษุก็ยังมีทิฐิมานะไม่ยอมเลิก จนญาติโยมต้องขู่ว่าหากไม่เลิกก็จะไม่ใส่บาตรแล้ว สถานการณ์จึงค่อยสงบลง โดยมีพระอานนท์พาคณะสงฆ์ไปขอขมาพระพุทธเจ้า

ข้อคิดจากเรื่องนี้คือความสำคัญของ “ข้อมูลที่ครบถ้วนสมบูรณ์ (Information Integrity)” เพราะการได้รับข้อมูลไม่หมดจะนำไปสู่การแบ่งฝักแบ่งฝ่ายทะเลาะเบาะแว้งกัน ต่างคนต่างถือความเป็นพวกเขา-พวกเรา ความสงบสุขจึงไม่เกิดขึ้น จึงอยากชวนให้ “เปลี่ยนตั้งแต่มโนกรรม” คือสร้างความตระหนักเรื่องการบอกข้อมูลไม่หมด เพราะแม้จะไม่มีเจตนาแต่ผู้ที่ฟังก็อาจนำไปตีความต่อแบบผิดๆ แล้วเกิดความเสียหายตามมาได้ จึงต้องระมัดระวังตั้งแต่ต้น
“ตอนนี้สิ่งที่เกิดในสังคมไทยและหลายๆ สังคม คือบางทีสังคมปล่อยให้ปัจเจกทำแบบนี้ได้ ไม่ว่าจะโดยเห็นว่าเขายังเด็กไม่รู้เรื่องอะไร หรือเขาเป็นผู้ใหญ่มีอำนาจ สุดท้ายมันเกิดปัญหา เหมือนที่เราเห็นปัญหาจากการใช้ประโยชน์จากขายตรง แต่ใช้ไปในแบบไม่ถูกทิศทาง วันนี้ก็เห็นปัญหา ต้องบอกว่าหลายคนที่ทำขายตรงแบบสุจริตตรงไปตรงมาได้รับผลกระทบไปเยอะมาก แม้แต่บริษัทข้ามชาติที่ทำเรื่องนี้ เท่าที่อาตมาทราบปลดคนไปเยอะเพราะสิ่งเหล่านี้ จะเห็นว่าพอไม่มีเรื่องข้อมูลที่ครบถ้วนสมบูรณ์ ไม่มีความรับผิดชอบกับสิ่งที่ตัวเองคิด-พูด-ทำ พอปล่อยให้เกิดกับปัจเจกแล้วสังคมก็ไม่รับผิดชอบด้วยเพราะคิดว่าไม่เป็นไร สุดท้ายก็เกิดปัญหาใหญ่” พระมหานภันต์ฝากข้อคิด

ด้าน สุภิญญา กล่าวถึงสถานการณ์ข่าวลวงและมิจฉาชีพออนไลน์ว่า ปัจจุบันมิจฉาชีพใช้ “ซิมบ็อกซ์ (Sim Box)” เป็นอุปกรณ์ที่ช่วยให้โทรศัพท์แบบสุ่มไปหาเป้าหมายได้ทีละมากๆ แบบไม่ต้องมาไล่กดที่ละหมายเลข ซึ่งแม้จะผิดกฎหมายแต่ไม่รู้ว่าเกลื่อนประเทศไทยได้อย่างไร ซึ่งงานของโคแฟคในปีนี้อาจต้องเน้นที่การผลักดันข้อเสนอแนะเชิงนโยบายมากขึ้น จากตลอด 4 ปีที่ผ่านมาที่เน้นรณรงค์ให้ทุกคนช่วยกันตรวจสอบข่าวลวง อย่างไรก็ตาม จากนโยบายล่าสุดของเฟซบุ๊ก การที่แต่ละคนช่วยกันตรวจสอบก็ยังจำเป็นอยู่
หากให้ประเมินผลงานที่ผ่านมา ในเชิงการดำเนินงาน ก็น่าจะสอบผ่าน แต่ในเชิงผลลัพธ์ อาจผ่านและไม่ผ่านในบางเรื่อง โดยสิ่งที่ประสบความสำเร็จ คือโคแฟคได้ขยายแนวคิดเรื่องการตรวจสอบข้อเท็จจริงและการสร้างฐานข้อมูล แต่ปัญหาที่พบคืองานของโคแฟคยังไม่เป็นที่รู้จักในวงกว้างมากพอ กล่าวคือ หากเป็นคนในวงการหรือภาคีเดียวกัน เช่น องค์กรสื่อ องค์กรผู้บริโภค จะรู้จักโคแฟค แต่ถ้าออกไปตามท้องถนนผู้คนก็อาจไม่รู้จักดังนั้นแผนของปี 2568 โคแฟคอาจต้องทำงานกับคนที่ชำนาญในเรื่องนี้มากขึ้น

“อาจต้องทำแคมเปญร่วมกัน เช่น อาจชวน IBHAP ทำแคมเปญบริจาคข่าวลวงได้บุญ เข้าสู่ฐานข้อมูล แล้วก็ทำกันทั้งปี ไปทำบุญที่ไหนนอกจากถวายเพลแล้วก็ช่วยกันบริจาคข่าวลวงเข้าฐานข้อมูล แล้วถ้าใครบริจาคได้เยอะก็อาจมีอะไรให้เป็นแรงจูงใจ เป็นการทำแคมเปญร่วมกัน เราทำฐานข้อมูลมาแล้ว cofact.org มีข้อมูลเยอะมาก เว็บไซต์ก็มีข้อมูลดีๆ เยอะมาก แต่มันอาจจะเข้าถึงยาก อาจจะดูอ่านยาก ทำอย่างไรจะให้ย่อยมากขึ้น” สุภิญญา กล่าว
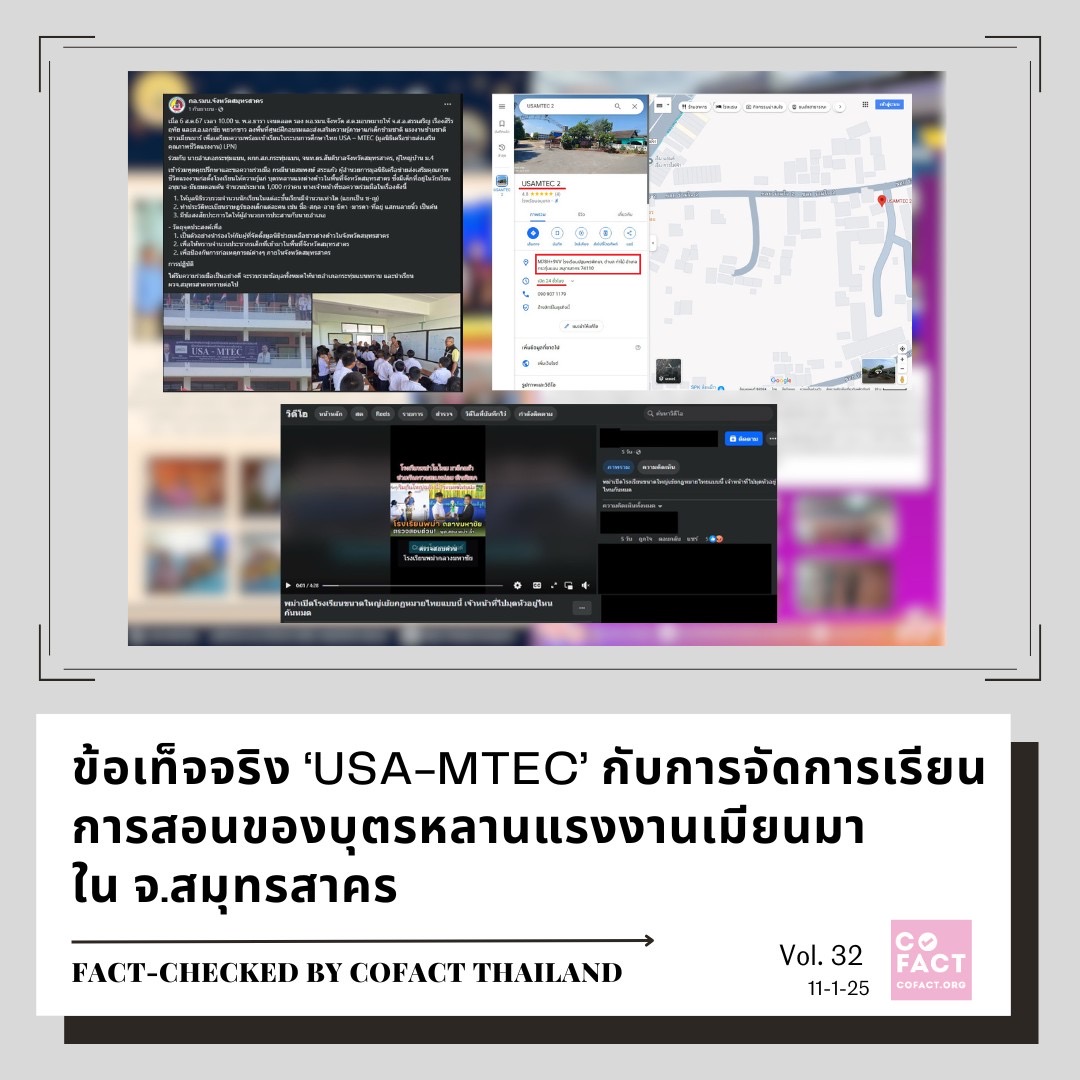
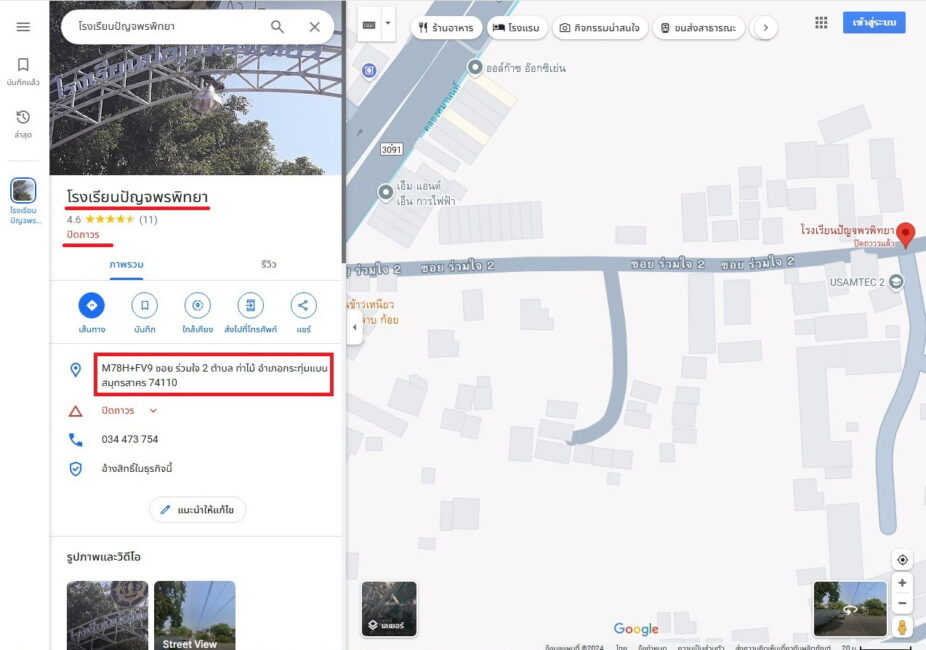
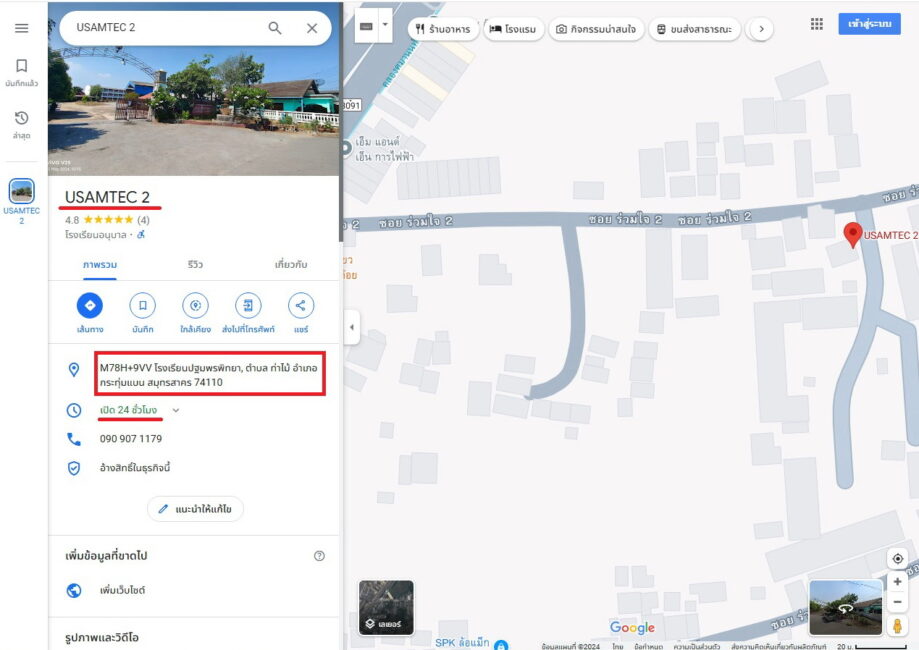
ประการต่อมา โคแฟคอาจต้องทำงานกับสื่อมวลชนอย่างจริงจังมากขึ้น เช่น มีความร่วมมือกับบางองค์กรเพื่อช่วยกันตรวจสอบข้อเท็จจริง เป็นงานเชิงคุณภาพที่มีผลงานออกมาทุกเดือนหรือทุกสัปดาห์ อาทิ ที่ผ่านมาโคแฟคจับประเด็นความขัดแย้งทางศาสนาอย่างความเกลียดกลัวอิสลาม (Islamophobia) แต่ในช่วงปลายปี 2567 ก็มีประเด็นการเผยแพร่คลิปวีดีโอที่ทำให้เกิดความเกลียดชังแรงงานจากประเทศเพื่อนบ้าน อ้างว่ามีแรงงานข้ามชาติมาคลอดลูกเต็มโรงพยาบาลทำให้คนไทยไม่สามารถคลอดลูกได้ โดยเรื่องนี้เป็นความเข้าใจคลาดเคลื่อน (Misinformation) ซึ่ง “ข่าวลวงที่ทำให้เกิดความเกลียดชังยังคงมีอยู่แต่เป็นแบบซึมลึก วันใดที่มีอะไรไปกระตุ้นก็อาจกลายเป็นความรุนแรงได้” งานในระยะต่อไปอาจเป็นการตรวจสอบเชิงป้องกัน (Prebunking) มากขึ้น ซึ่งดีกว่าการตรวจสอบแบบตามหลังเหตุการณ์ (Debunking) อย่างเรื่องการเมืองก็อาจกลับมาร้อนแรงได้อีกในปี 2568 นี้เช่นกัน!!!
สามารถรับชมย้อนหลังได้ที่ https://www.facebook.com/CofactThailand/videos/464090773409196/
-/-/-/-/-/-/-/-/-/-/-
อ้างอิง
https://www.bbc.com/thai/articles/c1kek7zjz41o (เหตุใดเฟซบุ๊กและอินสตาแกรมจึงยกเลิกการใช้เครื่องมือตรวจสอบความจริง : BBC ไทย 8 ม.ค. 2568)