เราจะหยุดยั้งการระบาดของข่าวลวงด้วย Super-corrector ได้อย่างไร
ผลการวิเคราะห์ข่าวลวงเรื่อง Covid-19 ชี้ให้เห็นว่าข่าวลวงจะแพร่กระจายน้อยลงเมื่อมีองค์กรสื่อและโซเชียลมีเดียที่มีผู้ติดตามมากเป็นผู้แก้ข่าวนั้นพร้อมๆกันทันทีหลังพบ Super-spreader
ชิตพงษ์ กิตตินราดร และทีมวิจัย
สถาบันเชนจ์ฟิวชั่น (ChangeFusion)
เมษายน 2563
ปัญหาการแพร่กระจายของข้อมูลเท็จ หรือที่เรียกว่าข่าวลวง เป็นปัญหาที่มีความรุนแรงมากขึ้นเรื่อยๆ และส่งผลต่อชีวิตและสังคมอย่างจับต้องได้ ตัวอย่างเช่นในช่วงเวลาปัจจุบันที่โรค COVID-19 กำลังแพร่ระบาดไปทั่วโลก ข่าวลวงและข้อมูลเท็จเกี่ยวกับการตรวจหาโรค การป้องกันตัว และการรักษา ล้วนส่งผลกระทบต่อชีวิตของคน เพราะถ้าผู้รับข่าวนำเนื้อหาในข่าวลวงไปปฏิบัติ ก็จะทำให้เกิดความเสี่ยงที่จะเกิดปัญหาทั้งต่อตนเอง ชุมชน และสังคมได้
การแก้ปัญหาข่าวลวง จึงเป็นวาระที่สำคัญของสังคม องค์กรสื่อ ภาคประชาชน และรัฐบาล ต่างเริ่มตื่นตัวจริงจังในการแก้ปัญหา โดยเกิดศูนย์ข่าวที่มีภารกิจในการแก้ไขข่าวลวงโดยเฉพาะ ควบคู่ไปกับการดำเนินการคล้ายคลึงกันของเพจที่ได้รับความนิยมบนเครือข่ายสังคม อย่างไรก็ตาม ในสังคมไทยแทบจะยังไม่มีการศึกษาเกี่ยวกับธรรมชาติของข่าวลวงว่ามีคุณลักษณะด้านต่างๆ อย่างไร และวิธีการไหนจะสามารถหยุดหรือป้องกันการแพร่กระจายของข่าวลวงได้ดีที่สุด การขาดความรู้นี้ทำให้การดำเนินการต่างๆ เกี่ยวกับข่าวลวงขาดความมั่นใจและสิ่งยืนยันว่าดำเนินการอย่างตรงจุดและได้ผล
เมื่อต้นปี 2563 ในช่วงที่ COVID-19 เริ่มระบาด ผู้เขียนได้มีโอกาสร่วมพัฒนาโครงการ Cofact ประเทศไทย ซึ่งมีเป้าหมายในการสร้างกลไกการตรวจสอบข่าวลวง ผ่านเว็บไซต์ cofact.org ควบคู่ไปกับการสร้างเครือข่ายออนไลน์ของอาสาสมัครที่ทำงานตรวจสอบข่าวลวง หนึ่งในปัจจัยสำคัญที่จะทำให้ Cofact บรรลุถึงเป้าหมายนี้ได้ คือการพยายามตอบคำถามว่า “ข่าวลวงเป็นอย่างไร มีพฤติกรรมอย่างไร และจะหยุดยั้งการระบาดได้อย่างไร” ผู้เขียนจึงได้พัฒนากระบวนวิธีที่จะทำให้ได้มาซึ่งคำตอบดังกล่าว
กระบวนการ เริ่มด้วยใช้ข้อมูลจากโซเชียลมีเดีย เช่น Facebook, Twitter, Instagram, Youtube, บล็อก และเว็บข่าวต่างๆ ซึ่งรวบรวมโดยบริการ Zocial Eye ของบริษัท Wisesight โดยข้อมูลแต่ละรายการ ประกอบด้วยวัน เวลา, ข้อความ, แพลตฟอร์ม, URL, Engagement เป็นต้น
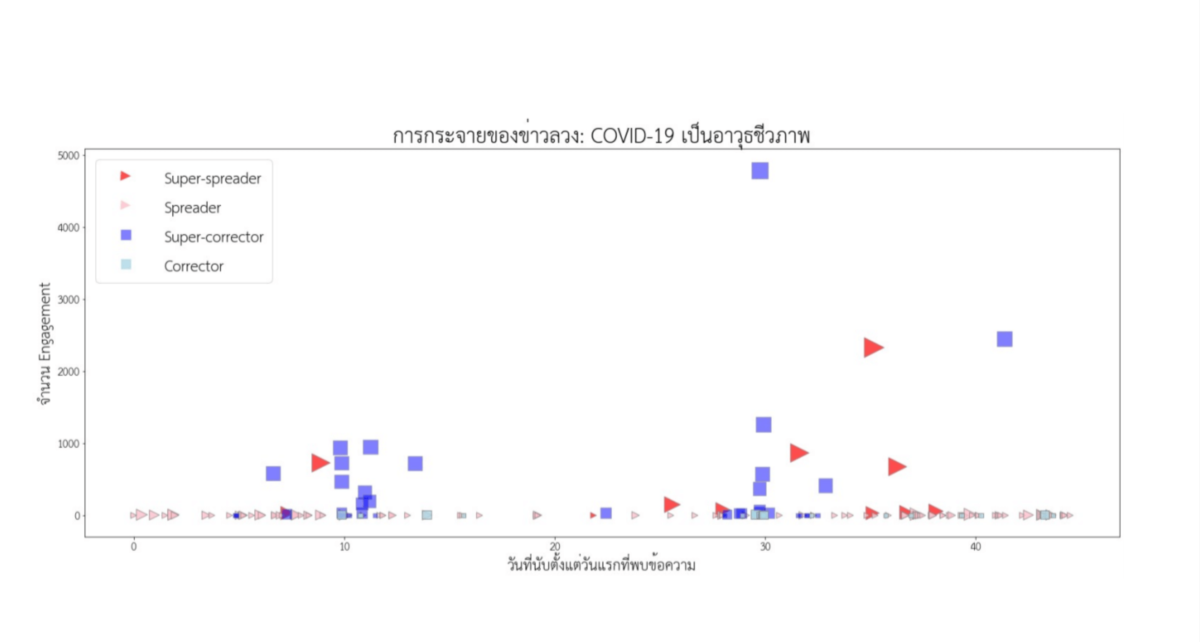
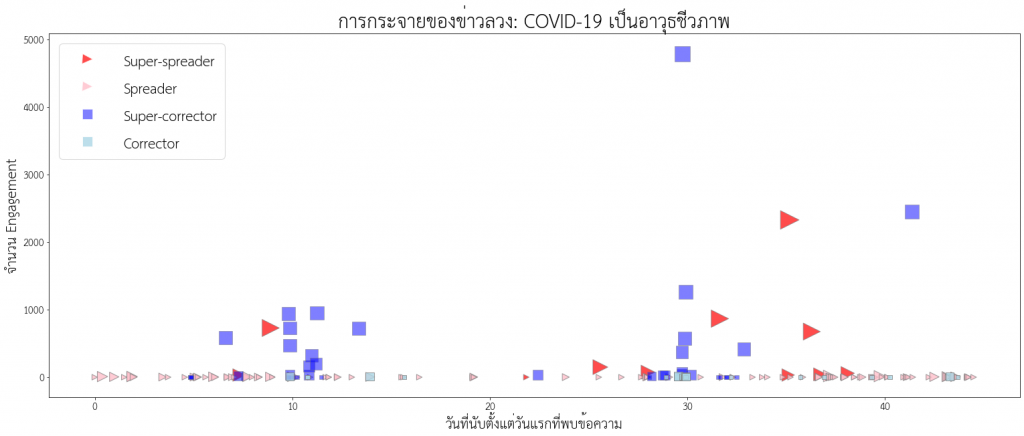
จากนั้น นำข้อมูลโซเชียลมีเดียที่มีคำหรือกลุ่มคำตามหัวข้อที่สนใจ มาพล็อตดูรูปแบบการกระจายตัวหรือการกระจุกตัวของข้อความ โดยรูปแบบนี้จะพิจารณาเทียบกับเวลาที่นับตั้งแต่ข้อความแรกปรากฏ ร่วมกับจำนวนปฏิสัมพันธ์ (Engagement) ของแต่ละข้อความ เช่นตัวอย่างหัวข้อ “COVID-19 เป็นอาวุธชีวภาพ” พบว่ามีข้อความที่เกี่ยวข้อง กระจุกตัวเป็นสองกลุ่ม นั่นคือกลุ่มแรก รวมศูนย์อยู่ที่ประมาณวันที่ 10 หลังจากที่พบข้อความแรก และกลุ่มที่สอง รวมศูนย์อยู่ที่ประมาณวันที่ 30 หลังจากที่พบข้อความแรก
เพื่อทำให้การวิเคราะห์เกิดประโยชน์ จึงจำแนกข้อความข่าวแต่ละข้อความเป็นสี่ประเภท ได้แก่
- Super-spreader คือข้อความที่เผยแพร่ข้อมูลที่ผิด ที่มี Engagement มากกว่า 30 ครั้ง หรือเผยแพร่โดยสำนักข่าวหรือเว็บไซต์ที่มีชื่อเสียง
- Spreader คือข้อความที่เผยแพร่ข้อมูลที่ผิด ที่เผยแพร่โดยบัญชีเครือข่ายสังคมหรือกระทู้บนเว็บบอร์ดโดยคนทั่วไป
- Super-corrector คือข้อความที่แก้ไขข้อมูลที่ผิด ที่มี Engagement มากกว่า 30 ครั้ง หรือเผยแพร่โดยสำนักข่าวหรือเว็บไซต์ที่มีชื่อเสียง
- Corrector คือข้อความที่แก้ไขข้อมูลที่ผิด ที่เผยแพร่โดยบัญชีเครือข่ายสังคมหรือกระทู้บนเว็บบอร์ดโดยคนทั่วไป
ทั้งนี้ การจำแนกประเภทของข้อความจะดำเนินการโดยการอ่านและวิเคราะห์เนื้อหาข่าวลวงทีละเรื่อง
เมื่อแบ่งประเภทข้อความตามเกณฑ์ข้างต้น พบว่าจาก 194 ข้อความที่พบ เป็น Super-spreader 11 ข้อความ (5.67%), Spreader 119 ข้อความ (61.34%), Super-corrector 42 ข้อความ (21.64%), และ Corrector 22 ข้อความ (11.34%)
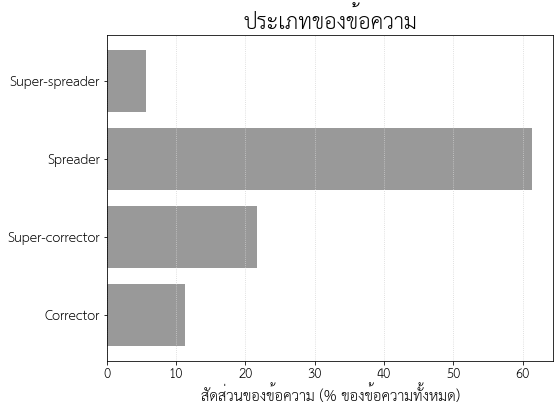
เห็นได้ว่า ในบรรดากลุ่มข้อความที่แพร่ข่าวลวง Spreader ทั่วไปมีจำนวนมากกว่า Super-spreader มาก ในขณะที่สัดส่วนของกลุ่มผู้แก้ข่าวนั้นเป็นทางตรงกันข้าม นั่นคือ Corrector มีจำนวนน้อยกว่า Super-corrector นั่นหมายถึงว่าคนทั่วไปมีแนวโน้มที่จะกระจายข่าวลวงที่ได้รับมา แต่ไม่ค่อยจะเป็นผู้แก้ข่าวเมื่อได้รับข้อมูลใหม่ที่เป็นความจริง
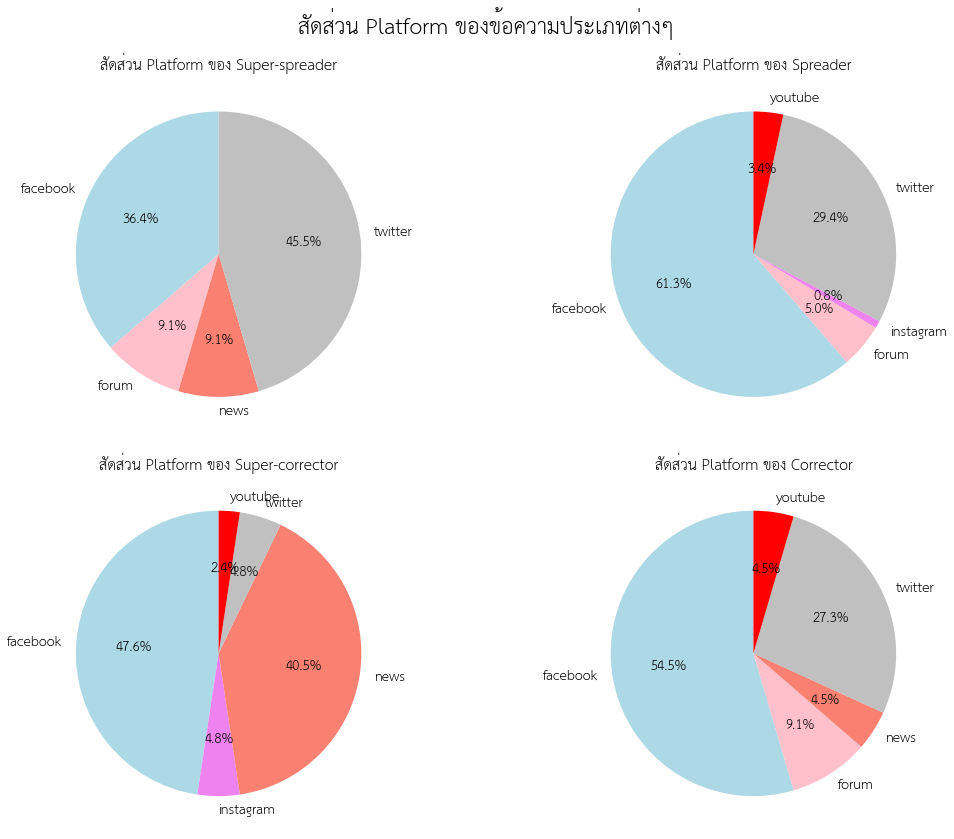
ต่อมา เมื่อพิจารณาดูสัดส่วนของแพลตฟอร์มที่พบข่าวลวงและการแก้ข่าวลวง พบว่า Facebook และ Twitter เป็นแพลตฟอร์มยอดนิยมของทุกกลุ่ม อย่างไรก็ตาม พบว่า Super-corrector มีสัดส่วนที่จะอยู่บนเว็บข่าวสูง ซึ่งชี้ให้เห็นว่า องค์กรสื่อมีบทบาทสูงในการเป็นผู้แก้ข่าวลวง
ขั้นตอนต่อมา คือการพิจารณาปฏิสัมพันธ์ระหว่างข้อความที่อยู่ในบทบาทต่างๆ โดยดูรูปแบบการปรากฏและความสัมพันธ์ของข้อความในบทบาทต่างๆ ภายในกลุ่มกระจุกตัว (Cluster) เดียวกัน พบข้อสังเกตที่น่าสนใจ คือการระบาดของข่าวลวงในกลุ่มกระจุกตัวหนึ่งๆ มีแนวโน้มที่จะยุติลง (จำนวน Spreader ลดลงจนแทบจะหายไป) หากกลุ่มกระจุกตัวนั้นมี Super-corrector จำนวนมากแก้ข่าวในเวลาไล่เลี่ยกันหลังจากที่พบข้อความประเภท Super-spreader ในทางกลับกัน หากกลุ่มกระจุกตัวนั้นขาด Super-corrector ข่าวลวงก็จะระบาดต่อไปโดย Spreader ที่มีจำนวนไม่ลดลง
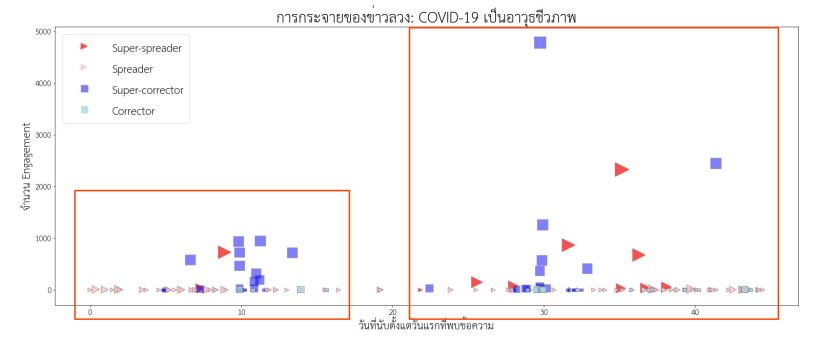
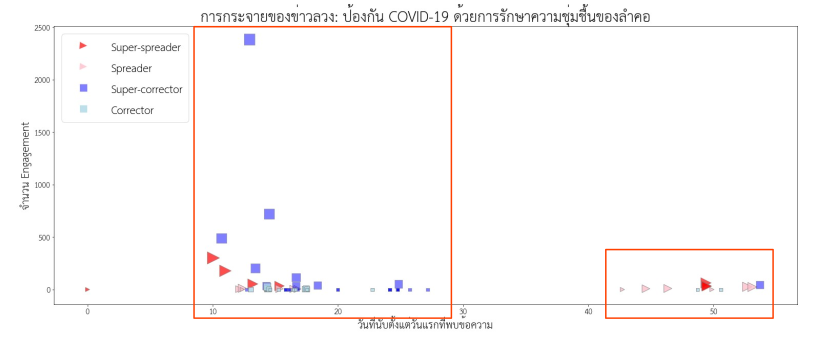
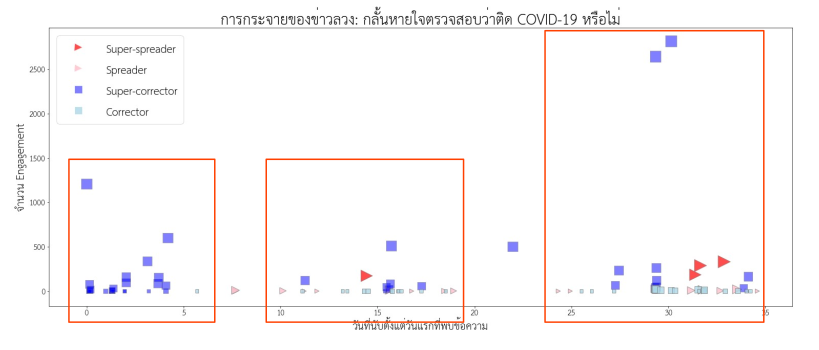
นั่นหมายความว่า การทำงานร่วมกันอย่างเป็นระบบ (Coordinated effort) และทันท่วงที (Timely) ขององค์กรสื่อและสื่อโซเชียลมีเดียที่มีผู้ติดตามจำนวนมากในการแก้ข่าวลวง เป็นเงื่อนไขที่สำคัญในการหยุดยั้งการระบาดของข่าวลวง
สุดท้าย เราสามารถวิเคราะห์เนื้อหา (Text analysis) ของข้อความในการระบาดแต่ละระยะ โดยแบ่งการระบาดภายในกลุ่มกระจุกตัวแต่ละกลุ่มออกเป็นสองระยะ คือระยะเริ่มต้น กับระยะพัฒนา
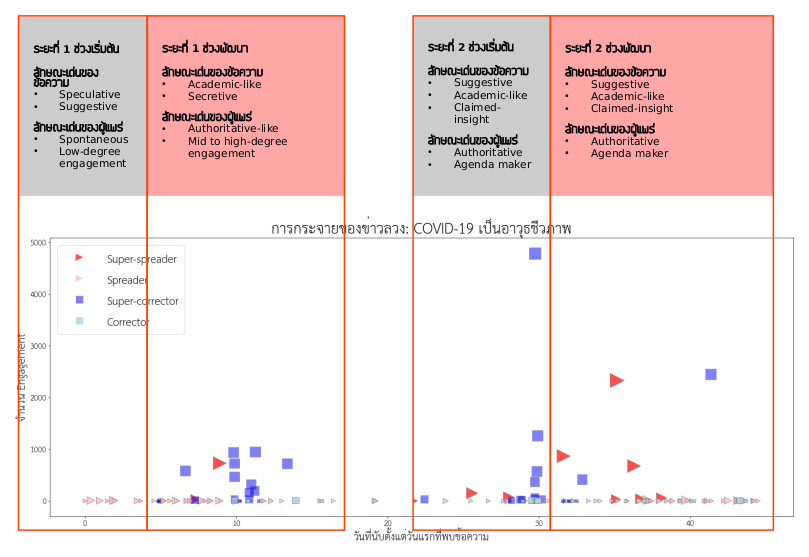
จะพบว่าในระยะเริ่มต้น การระบาดมักจะเริ่มโดย Spreader ในลักษณะการพูดลอยๆ เป็นความคิด ข่าวลือ ในขณะที่การระบาดในระยะพัฒนา เนื้อหาจะดูมีความน่าเชื่อถือ เป็นวิชาการ หรืออ้างว่ามีที่มาที่เป็นความลับ เป็นต้น อย่างไรก็ตาม ข้อสังเกตนี้ไม่ได้เป็นจริงในทุกกรณี ขึ้นอยู่กับลักษณะเนื้อหาของข่าวนั้นๆ
นอกจากเรื่อง COVID-19 เป็นอาวุธชีวภาพแล้ว ผู้เขียนได้ใช้วิธีการนี้วิเคราะห์ข่าวลวงเรื่องการตรวจ COVID-19 ด้วยการกลั้นหายใจ 10 วินาที, การป้องกัน COVID-19 ด้วยการรักษาความชุ่มชื้นของลำคอ, และการดื่มน้ำอุ่นเพื่อฆ่าเชื้อ COVID-19 รวมสี่เรื่อง ซึ่งได้ผลใกล้เคียงกับข้อสังเกตจากเรื่องแรกที่ได้อธิบายไป (ยกเว้นการวิเคราะห์เนื้อหาที่แตกต่างกันไปตามลักษณะเนื้อหาของแต่ละข่าว)
ดังนั้น อาจสรุปได้ว่า ผลการศึกษาจากตัวอย่างเรื่อง COVID-19 ทั้งสี่หัวข้อโดยใช้กระบวนวิธีนี้ ชี้ให้เห็นถึงบทบาทและความสำคัญของกลุ่ม Super-corrector ซึ่งเป็นผู้แก้ข่าวลวง ที่เป็นได้ทั้งองค์กรสื่อ ศูนย์ตรวจสอบข่าวลวง เพจหรือผู้ใช้โซเชียลมีเดียที่มีผู้ติดตามสูง ที่ต้องคอยติดตาม ตรวจสอบ และเผยแพร่เนื้อหาแก้ไขความเชื่อ ความเข้าใจที่ผิด โดยจะมีโอกาสสูงในการหยุดยั้งการระบาดได้เมื่อ Super-corrector ร่วมกันแก้ไขข่าวนั้นอย่างรวดเร็วและพร้อมเพรียงกันเมื่อพบการระบาด
ข้อจำกัดและโอกาสในการพัฒนาการวิเคราะห์ข่าวลวง
การศึกษาโดยใช้กระบวนวิธีนี้ในครั้งนี้ เป็นความพยายามแรกๆ ในประเทศไทย ในการศึกษาเรื่องการระบาดและการหยุดยั้งการระบาดของข่าวลวงอย่างเป็นระบบ ซึ่งยังมีข้อจำกัดที่สำคัญ เช่น:
- กระบวนวิธี: เป็นการศึกษาความสัมพันธ์ระหว่างข้อมูลประเภทต่างๆ ที่สรุปผลจากระดับความสัมพันธ์ (Correlation) ไม่ใช่การยืนยันเหตุและผล (Causation) กล่าวคือเป็นการสรุปผลจากรูปแบบความสัมพันธ์ “ที่เห็น” ซึ่งไม่ได้หมายความว่าสิ่งที่เห็นต้องมีเหตุและผลเกี่ยวข้องกัน ดังนั้น การสรุปว่า “เมื่อมีสิ่งนี้ จึงพบสิ่งนี้” จึงไม่ได้หมายความว่า “เมื่อมีสิ่งนี้ จึงนำไปสู่สิ่งนี้” การยืนยันเหตุและผลของความสัมพันธ์ ไม่ใช่ขอบเขตของการศึกษานี้ ซึ่งสามารถทำได้ด้วยการทดลองอย่างเป็นวิทยาศาสตร์โดยการควบคุมตัวแปร หรือด้วยการเก็บข้อมูลที่ยืนยันความสัมพันธ์ระหว่างข้อความแต่ละประเภทได้ เช่นการยืนยันว่าข้อความของ Super-corrector “A” มาจากการที่ “A” เห็นข้อความนั้นจาก Super-spreader “B” ซึ่งเป็นข้อมูลที่เครื่องมือปัจจุบันไม่สามารถได้มาหรือยืนยันได้โดยง่าย
- ข้อมูลที่นำมาศึกษา: มีขนาดเล็ก จำกัดเพียงแค่ข่าวสี่หัวข้อเรื่อง COVID-19 เท่านั้น ซึ่งแต่ละหัวข้อ สามารถเก็บข้อมูลโซเชียลมีเดียที่เจ้าของเนื้อหาเปิดเผยเป็นสาธารณะเท่านั้น และไม่รวมเนื้อหาใน LINE ซึ่งไม่สามารถเข้าถึงได้เลยหากไม่ใช่เจ้าของหรือสมาชิกในกลุ่ม ข้อจำกัดนี้ทำให้ผลการศึกษาอาจไม่เป็นจริงในทุกกรณี
ดังนั้น หากผู้สนใจต้องการที่จะต่อยอดพัฒนากระบวนวิธีนี้ให้ดียิ่งขึ้น ผู้เขียนแนะนำให้มุ่งเน้นการพัฒนาในเรื่องดังต่อไปนี้:
- กระบวนวิธี: พัฒนาหรือออกแบบกระบวนวิธีที่จะสามารถยืนยันความสัมพันธ์เชิงเหตุและผล (Causation) เพื่อสนับสนุนระดับความสัมพันธ์ (Correlation) เช่น การหาวิธีเก็บและยืนยัน “การไหล” ของข้อมูลชิ้นหนึ่งๆ เป็นลำดับๆ และหาจุดที่ผู้รับข้อมูลชิ้นนั้นเปลี่ยนบทบาทจากผู้แพร่เป็นผู้แก้ไข
- ข้อมูลที่นำมาศึกษา: เก็บข้อมูลข่าวลวงประเด็นอื่นๆ และหัวข้ออื่นๆ ให้มากขึ้น และยืนยันข้อสรุปโดยการยืนยันนัยยะทางสถิติ (Statistical significance) ของสมมุติฐานเมื่อเทียบกับจำนวนข้อมูลทั้งหมด
บทความนี้เป็นส่วนหนึ่งของโครงการ Cofact ประเทศไทย